What is MLOps?
MLOps
- Machine Learning Operations의 약어
- 연구소에 머물고 있는 머신러닝 모델들을 실제 비지니스 환경(복잡하고 예측이 어려운 환경)에 운영하기 위한 기술들
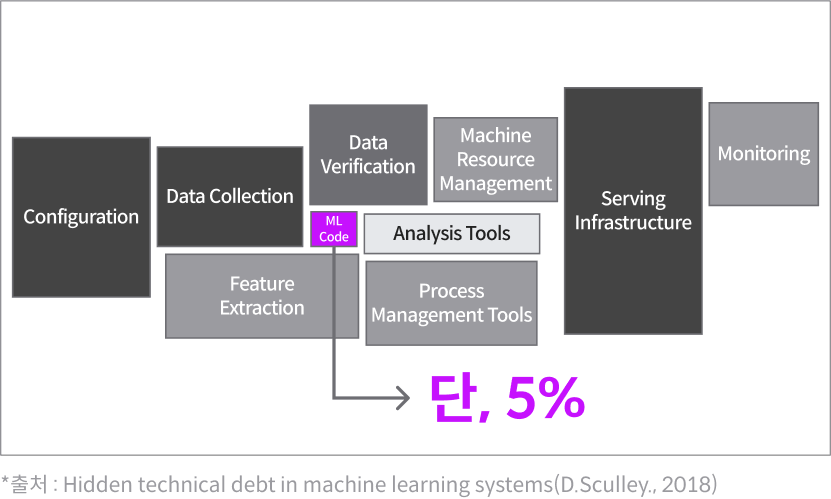

MLOps의 필요성
ML Model을 실제 비지니스 환경으로 적용할 때 문제점
- Model : 어떤 데이터를 넣으면, 어떤 결과가 나올 것인지를 규정하는 시스템을 의미한다.
- ML Modeling 과정에서는 아이디어를 검증하기 위해 예측 정확도가 중요하고, 많은 가정하에서 데이터를 학습하게 됨
- 실제 비지니스 환경에서는 굉장히 많은 복잡성과 불확실성이 있음 (서비스 안전성이 중요해짐)
- 특히 자원의 경우 모델이 좋아도 1개의 모델이 초당 고가의 GPU를 사용하게 된다면 서비스 양을 장담할 수 없게 됨
- 사용자의 트렌드에 따라 입력 데이터의 값이 수시로 변하기 때문에, 이 부분을 반영해서 운영하기는 쉽지 않음
- 데이터 처리 단계
- 예측 불가한 대량의 데이터 유입 (원하는 데이터를 찾기 어려움)
- 모델 학습
- 짧은 주기의 재 학습 (너무 많은 조합(데이터, 모델, 변수)으로 모델 재사용이 어려움)
- 대규모 학습 환경 구성 어려움
- 모델 서비스
- 모델의 예측 정확도가 불규칙함
- 다양한 변수 (자원 한계, 학습 환경과 운영 환경의 차이, 데이터 변동성 등)
ML Ops로 문제를 해결할 수 있는 영역
- 데이터 준비 단계
- 적시에 고품질 데이터를 제공
- ML Model 학습(실험) 단계
- 분석에 집중할 수 있는 환경 제공
- 모델 서비스 단계
- 비즈니스 가치에 집중할 수 있도록 함
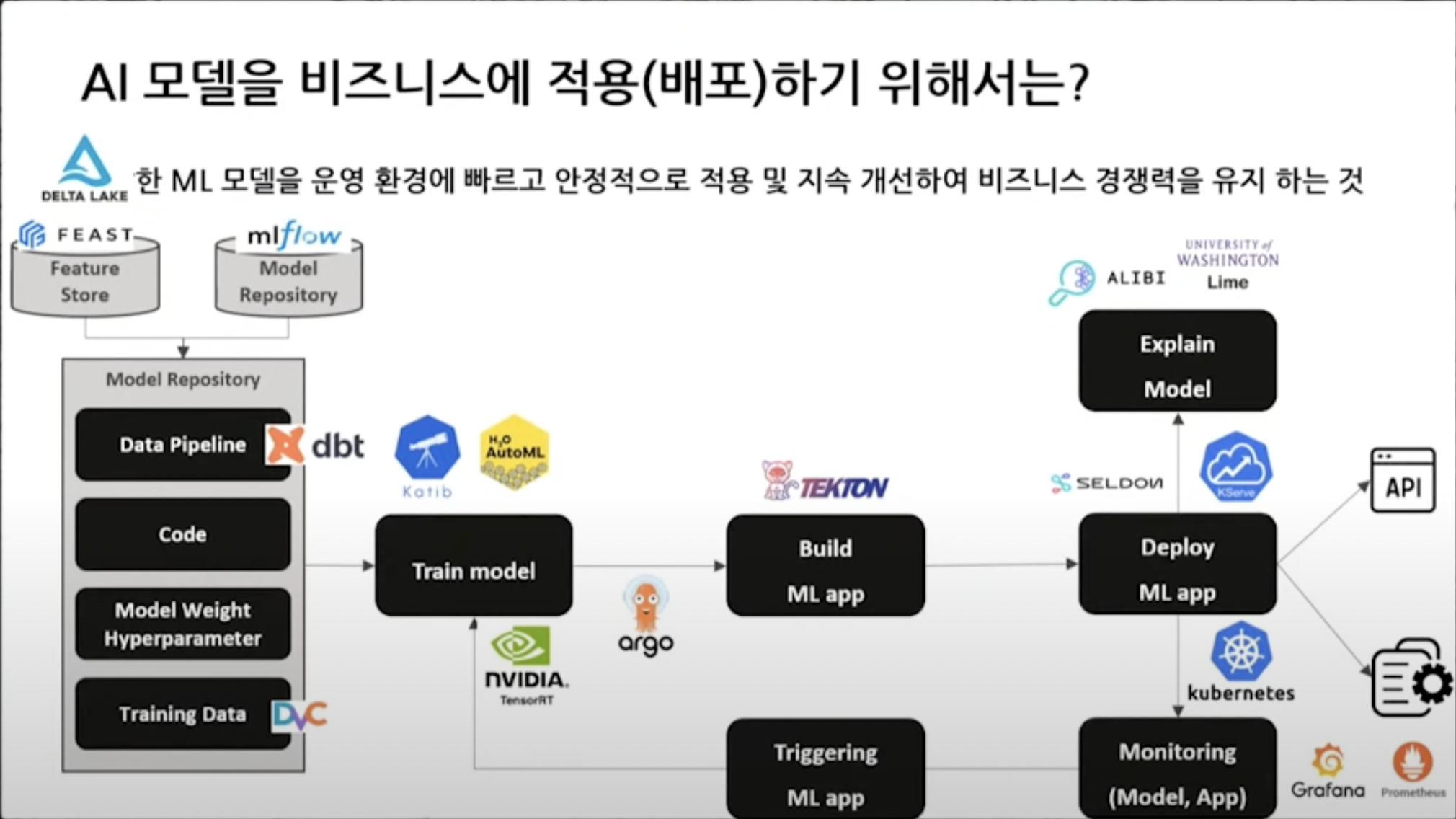
- 비즈니스 가치에 집중할 수 있도록 함
DevOps와 비교
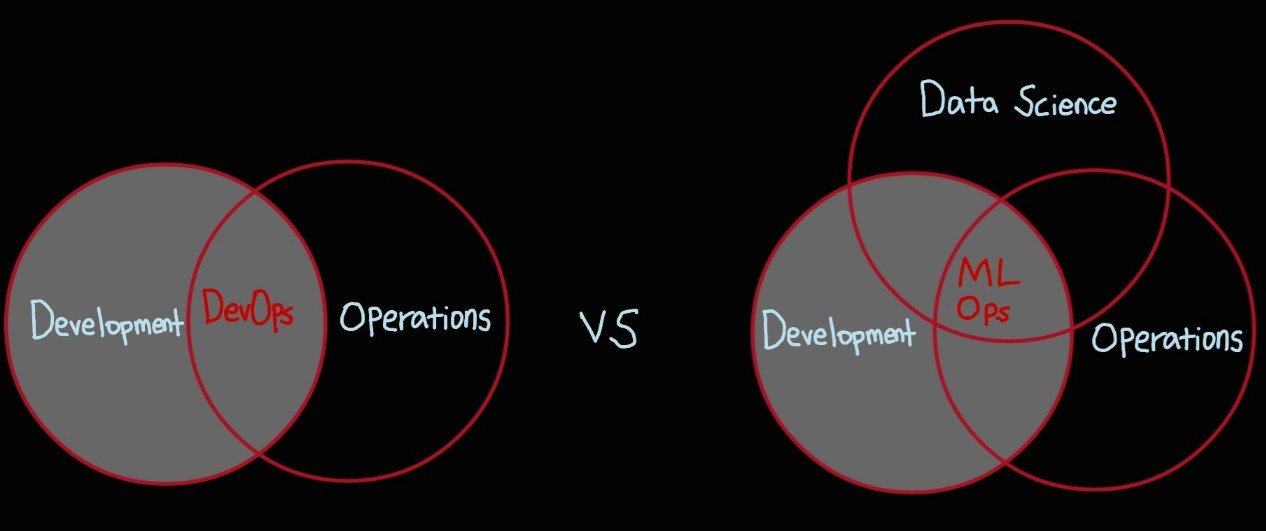
- DevOps
- 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화
- Application을 만들어 내는 과정 (개발 -> 운영 및 배포)
- CI(Continuous Integration), CD(Continuous Delivery)를 통해 개발팀과 운영팀의 장벽을 해제
CI(지속적 통합) : Application 개발 단계에서 코드 변경 사항을 자동으로 테스트하고 빌드하는 프로세스
CD(지속적 배포) : CI에서 생성된 Application을 자동으로 배포하는 프로세스
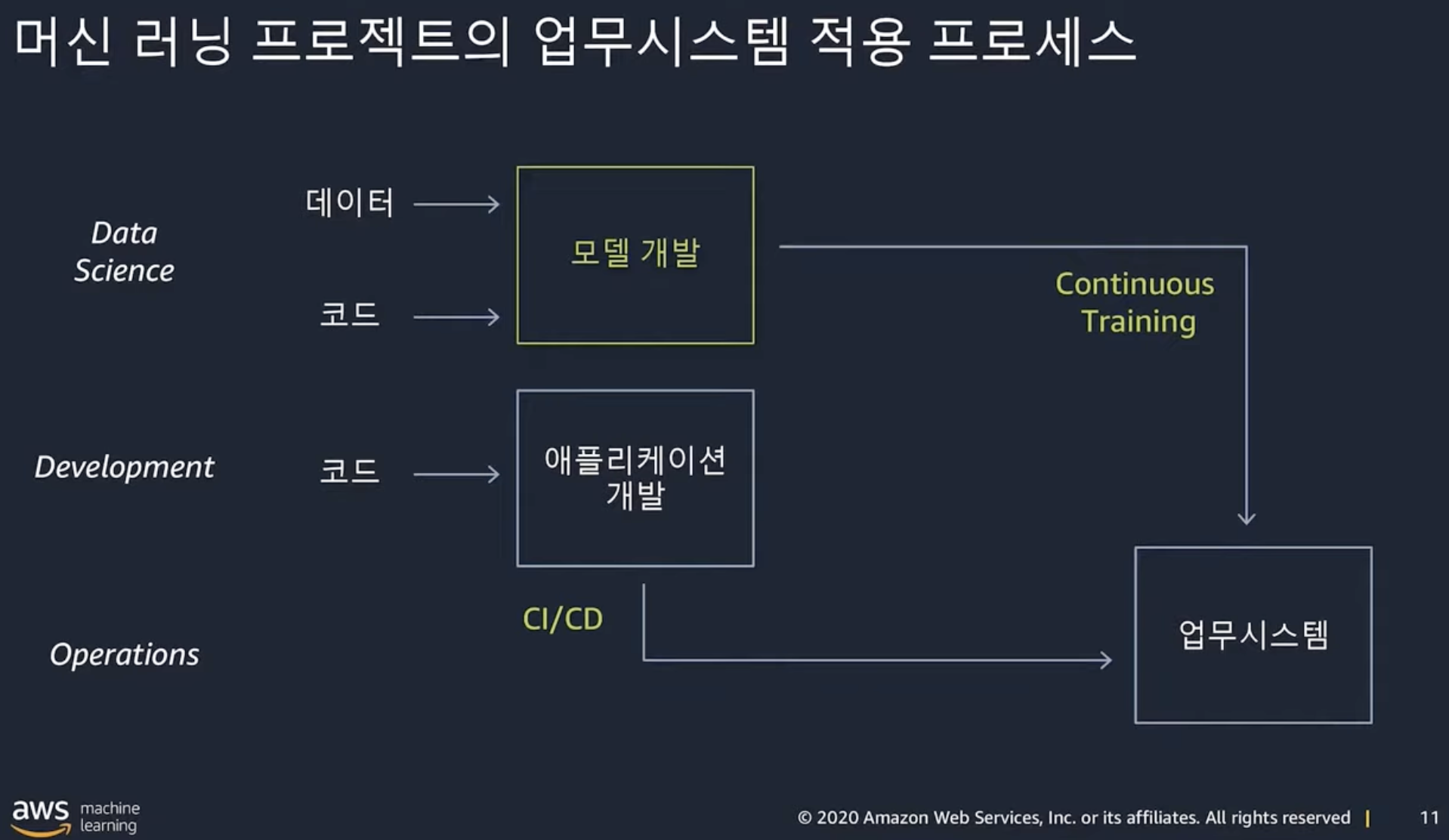
- MLOps
- DevOps에서 CI/CD 과정 외에 Continuous Training 이라는 용어가 추가
- 기존에 코드를 만들어서 유지,보수하다가 기능이 추가되면 코드를 추가해서 다시 배포하는 과정에서 머신러닝 모델이 새로운 데이터로 모델을 다시 학습시키고 배포
Data Pipeline, ML Pipeline
Pipeline : 라이프사이클(전체 돌아가는 프로세스)에 연결된 파이프라인으로 데이터가 흘러 들어가는 모습

Data Pipeline : data lake까지 data가 적재되기까지 정제 및 변환하는 일련의 흐름

용어 정리
- data lake : 구조화되거나 반구조화되거나 구조화되지 않은 대량의 데이터를 저장, 처리, 보호하기 위한 중앙 집중식 저장소(데이터를 기본 형식으로 저장할 수 있으며, 크기 제한을 무시하고 다양한 데이터를 처리 할 수 있음)
- data warehouse :트랜잭션 시스템, 운영 데이터베이스 및 사업 부서(LOB) 애플리케이션의 관계형 데이터 중앙 리포지토리
- data base : 여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 데이터들의 집합
- data mart : 단일 주제 또는 LOB에 초점을 맞춘 단순한 형태의 데이터 웨어하우스
- ML Pipeline : 데이터를 바탕으로 알고리즘에 넣으면 모델이 생성됨, 서비스 배포 과정에서 설정값(학습과 비슷한 환경으로 추론이 될 수 있도록)이 넘어가고, 라이브 데이터가 들어오면서 추론을 하게 됨
MLOps 적용 사례
kubernetes기반 ML Model Serving
Production 흐름
- ML Model API서버 만들기
- 파이썬에서 API서버 만들 수 있는 프레임워크 (ex: Flask)
- 서버
- docker image로 인스턴스에 띄우기
- 배포
- 운영팀의 피드백
- input 데이터에 잘못된 데이터 있는지 파악
- 모델 성능 모니터링, 모델 버전별로 관리
Kubeflow란?
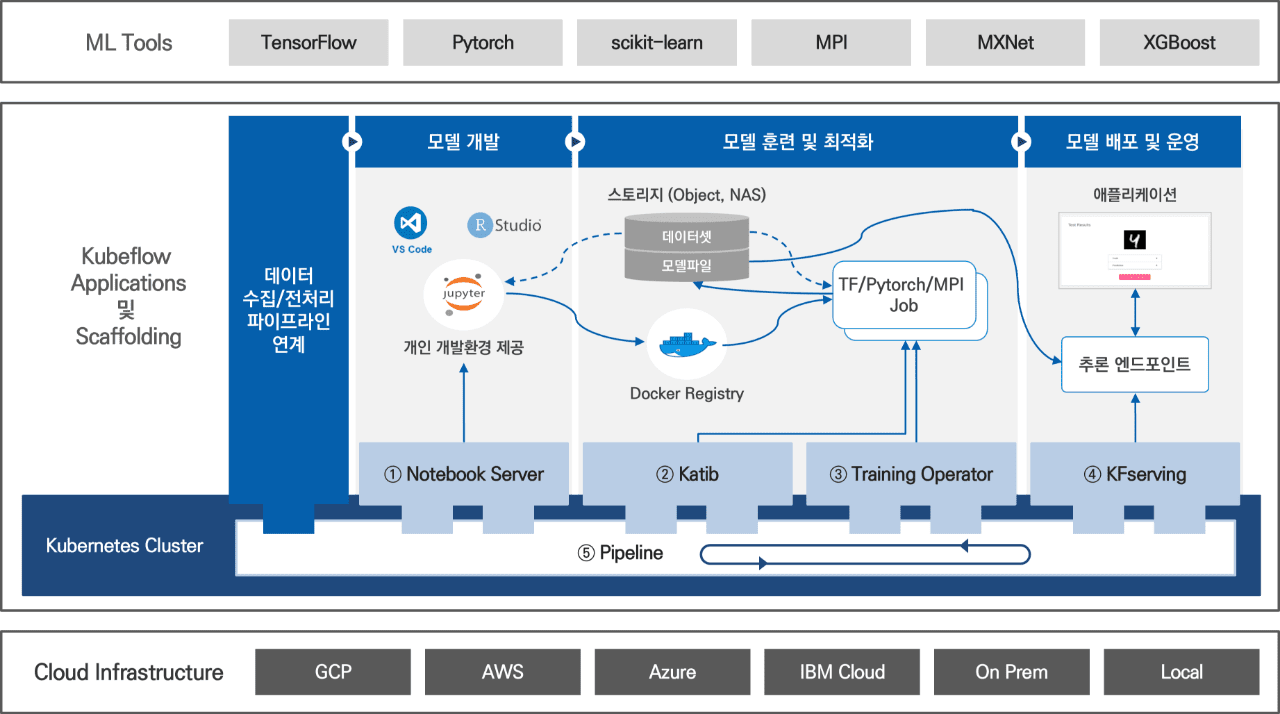
- kubernetes 위에서 간단하게 설치할 수 있는 ML Ops Open Source S/W
- 아래의 컴포넌트로 구성
- Training Operators
- KServing
- Katip
- Kubeflow Pipelines
- Notebooks, Centrol Dashboard
ML Model Serving
- 모델 서빙 : 학습된 ML 모델을 배포하고, 새로운 데이터를 입력받아 예측 결과를 출력하는 작업 (실시간 예측 시스템에서 중요한 역할)
- Istio
- kubernetes cluster
Knative
KServe
*출처
1.모두의 MLOps
2.머신러닝의 지속적 배포 및 자동화 파이프라인 환경인 MLOps 기술 소개와 적용 사례 공유
3.패스트캠퍼스
4.MLOps는 DevOps와 어떤 점이 다른가? [토크아이티 세미남 #24, AWS]
5.구글 클라우드
6.정의 및 비교) Data Warehouse, Data Base, Data Lake, Data Mart
7.[Openinfra & Cloud Native Day 2022] MLOps 쉽게 구현하는 ML Model Serving A to Z - 안승규
8.오픈소스를 활용한 Kubernetes 기반 MLOps 플랫폼 도입