의사결정나무 (decision tree)의 원리에 대해서 간략하게 알아보기.
머신러닝, 딥러닝은 통계학과 선형대수학(행렬, 벡터 등)을 기반으로 계산하는 기법들이 대다수임.
* 머신러닝은 주로 정형화된 데이터를 활용하고, 딥러닝은 비정형화된 데이터 (이미지, 음성, 비디오 등)를 활용
1. 기계학습(machine learning) 중에서 지도학습 (supervised) 중에서 분류 (classifier) 기법에 해당
2. 개요
- 뿌리(Root) : 최상위에 있는 노드 (node)의 분류가 시작되는 곳
- 부모(Parent) 노드 : 상위 노드
- 자식(Children) 노드 : 하위 노드
- 말단(Leaf) 노드 : 최하위에 있으며, 더 이상 분류되지 않는 노드

3. 원리
- 뿌리 노드에 전체 데이터가 속해 있으며, 상위 노드에서 하위 노드로 분류가 진행되어 나간다.
- 부모 노드보다 자식노드들이 순수한 노드가 되도록 반복적으로 나누어 간다.
- 위 예시 그림에서 (c)가 (a), (b)보다 분류된 결과의 순수도가 높다.
[테니스 예측 데이터]
- 날씨 조건에 따라 테니스 경기 여부를 예측해보기
- 날씨 속성 : 전망(?), 온도, 습도, 바람
| Outlook | Temperature | Humidity | Windy | PlayTennis |
| Sunny | Hot | High | FALSE | No |
| Sunny | Hot | High | TRUE | No |
| Overcast | Hot | High | FALSE | Yes |
| Rainy | Mild | High | FALSE | Yes |
| Rainy | Cool | Normal | FALSE | Yes |
| Rainy | Cool | Normal | TRUE | No |
| Overcast | Cool | Normal | TRUE | Yes |
| Sunny | Mild | High | FALSE | No |
| Sunny | Cool | Normal | FALSE | Yes |
| Rainy | Mild | Normal | FALSE | Yes |
| Sunny | Mild | Normal | TRUE | Yes |
| Overcast | Mild | High | TRUE | Yes |
| Overcast | Hot | Normal | FALSE | Yes |
| Rainy | Mild | High | TRUE | No |
- Step 1) Calculate Impurity before Splitting (불순도 계산)
- Step 2) Calculate Information Gain for Each Attribute / 부모, 자식노드의 지니 계수 가중평균
- Step 3) Choose Attribute with the Highest Information Gain as the Root Node
(Root Node를 결정하는 과정은 주어진 데이터셋에서 가장 좋은 속성(Feature)을 선택하는 과정)
4. 불순도 (Impurity) 계산 과정
Q. 불순도가 의미하는 것은?
- 해당 feature에서의 불확실성을 나타낸다. 따라서 불확실성이 적은 feature를 찾는 것이 높은 예측력을 가져옴.
- 지니 계수 (Gini index)
Gini(S)=1−(p12+p22+…+pk2)
는 각 클래스의 비율
- 엔트로피 (Entropy)
E(S)=−p1⋅log2(p1)−p2⋅log2(p2)−…−pk⋅log2(pk)
는 각 클래스의 비율
- ChatGPT를 활용한 계산 과정 설명
먼저 계산을 시작하기 전에 각 feature에 대한 unique한 값들을 확인해야 합니다. 이것은 decision tree에서 분할 기준이 됩니다. 아래에서는 Outlook, Temperature, Humidity, Windy의 unique한 값들을 확인해보겠습니다.
- Outlook : Sunny, Overcast, Rainy (유닉값 3개)
- Temperature : Hot, Mild, Cool (유닉값 3개)
- Humidity : High, Normal (유닉값 2개)
- Windy : True, False (유닉값 2개)
이제 각 feature에 대해 엔트로피와 지니 계수를 계산해보겠습니다.
1. Outlook:
Entropy:
E(S)=−pSunny⋅log2(pSunny)−pOvercast⋅log2(pOvercast)−pRainy⋅log2(pRainy)
Gini Index:
여기서 은 각각 Sunny, Overcast, Rainy에서 테니스를 칠 확률입니다.
=> 계산 결과:
Entropy_Outlook ≈ 0.94
Gini_Outlook ≈ 0.66
# 1. Outlook 지니계수
1 - ((5/14)**2 + (4/14)**2 + (5/14)**2)2. Temperature:
Entropy:
Gini Index:
여기서 은 각각 Hot, Mild, Cool에서 테니스를 칠 확률입니다.
계산 결과:
Entropy_Temperature ≈ 0.91
Gini_Temperature ≈ 0.64
- 3. Humidity:
Entropy:
Gini Index:
여기서 은 각각 High, Normal에서 테니스를 칠 확률입니다.
계산 결과:
Entropy_Humidity ≈ 0.98
Gini_Humidity ≈ 0.5
4. Windy:
Entropy:
Gini Index:
여기서 은 각각 True, False에서 테니스를 칠 확률입니다.
계산 결과:
Entropy_Windy ≈ 0.98
Gini_Windy ≈ 0.48
Root Node 선택
- 주어진 속성들 중에서 각 속성을 기준으로 데이터를 나누었을 때, 분할 후의 엔트로피 또는 지니 계수의 감소량을 계산합니다.
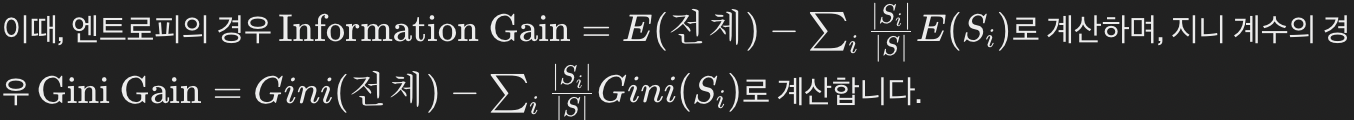
- 이를 각 속성에 대해 수행하고, 가장 정보 획득(또는 지니 감소)이 큰 속성을 선택하여 Root Node로 설정
5. Python 코드 및 싸이킷런 API로 실습
Q.학습한 모델은 이후에 어떻게 배포하는가?

* 출처 : https://www.itbiznews.com/news/articleView.html?idxno=33278
위에서 생성한 모델을 바탕으로, 오늘 또는 이번주 예상되는 날씨 데이터가 들어오면 테니스 play 여부에 대해 Yes / No 중에서 예측되는 값이 출력 될 것.
실습에서는 csv파일을 읽어오는 것으로 진행됐으나,
실제 서비스화 할 때는 데이터 레이크, 데이터 웨어하우스 등에 연결해서 데이터가 흘러 들어오면 모델 개발이 진행되고,
서비스화 하는 단계가 진행될 것으로 보임.
(이 과정에서 MLOps 엔지니어의 역할이 필요한 것 같다.)
+) MLOps 엔지니어 채용 공고 샘플

* 출처 : https://www.catch.co.kr/NCS/RecruitInfoDetails/348466
[참고자료]
1. https://medium.com/techhappily/decision-trees-a-simple-way-f165dc76e68f
'데이터 사이언스 스터디 > 머신러닝' 카테고리의 다른 글
| 클래스 불균형 문제 해결 방법 (샘플링 기법 비교) (0) | 2024.10.28 |
|---|